Księga wiedzy
Rozdziały: 1 2 3 4 5 6 7 8 9 10
Lista języków wzmiankowanych w Księdze Wiedzy i w innych działach strony.
POBIERZ PDF: Języki w niebezpieczeństwie: księga wiedzy: Wydanie I (2016).
Sprawdź się!
Sekcja Sprawdź się! – Rozdział 3. Zobacz, ile już wiesz lub czego możesz się jeszcze dowiedzieć z Księgi Wiedzy Języków w Niebezpieczeństwie!
Autor rozdziału: Nicole Nau
Szyk wyrazów w zdaniu
Pytania do rozstrzygnięcia
Jak wyrażać posiadanie
Jak pokazać strukturę wyrazów i fraz
Przypisy
Bibliografia
Języki różnią się od siebie pod względem sposobów łączenia elementów, które niosą znaczenie: tego, jak tworzone są słowa, a ze słów budowane zdania. Dział językoznawstwa badający budowę wyrazów to morfologia, a łączeniem się słów w większe wyrażenia i zdania zajmuje się składnia. W tym rozdziale zajmiemy się różnorodnością w strukturach języków świata i poznamy pewne podstawowe terminy i techniki używane do ich opisu.
Słowa w tekstach
Teksty składają się ze słów, ale by zrozumieć czy stworzyć tekst w jakimkolwiek języku, nie wystarczy znać znaczenia poszczególnych wyrazów. Słowa mogą przybierać różne formy w zależności od ich funkcji w zdaniu, a do łączenia słów w większe jednostki języki używają różnych technik. Nie można przetłumaczyć tekstu z jednego języka na drugi przekładając słowo po słowie. Języki różnią się od siebie pod względem informacji, jaką można (albo trzeba) ująć w jednym słowie. Dlatego liczba słów używana do oddania jednego znaczenia może być bardzo zróżnicowana w różnych językach. Porównaj tytuł Powszechnej Deklaracji Praw Człowieka w języku estońskim i tok pisin. Od razu widać, jak różnych technik używa się w tych dwu językach. Różnice da się też zaobserwować pomiędzy językami blisko spokrewnionymi genetycznie, takimi jak niderlandzki i niemiecki.
| język | “Powszechna Deklaracja Praw Człowieka” [1] | |
| estoński | Inimõiguste ülddeklaratsioon | 2 słowa |
| tok pisin | Toksave long ol raits bilong ol manmeri long olgeta hap bilong dispel giraun | 13 słów |
| niemiecki | Allgemeine Erklärung der Menschenrechte | 4 słowa |
| niderlandzki | Universele verklaring van de rechten van de mens | 9 słów |
Analizując te przykłady znajdujemy dwa powody, dla których liczby słów są różne. Po pierwsze, to co w jednym języku wyraża się kilkoma słowami, może być sformułowane za pomocą wyrazu złożonego w innym: „prawa człowieka” to po niemiecku Menschenrechte, wyraz złożony z Menschen ‘ludzie’ i Rechte ‘prawa’. Tak samo estoński łączy rzeczowniki inimene (rdzeń inim-) ‘człowiek’ i õigused ‘prawa’ w jedno słowo. W języku estońskim złożeniem jest również „powszechna deklaracja” (ülddeklaratsioon). Inną strategią słowotwórczą jest derywacja – na przykład niemieckie Erklärung zostało wyderywowane od czasownika erklären ‘tłumaczyć, deklarować’ za pomocą sufiksu -ung. Więcej przykładów tworzenia wyrazów złożonych i derywatów znajdziesz w dalszych częściach tego rozdziału.
Języki mogą też stosować więcej lub mniej wyrazów funkcyjnych – krótkich wyrazów, których używa się do łączenia innych słów i wyrażeń ze sobą lub do wyrażania znaczeń gramatycznych, na przykład mnogości czy określoności. W przykładzie z języka niderlandzkiego taką funkcję łączącą spełnia przyimek van, zaś de jest rodzajnikiem określonym, mającym podobne znaczenie co angielskie the. Odpowiednikiem niderlandzkiego van czy angielskiego of w języku tok pisin jest słowo bilong. Natomiast słowo ol w języku tok pisin oznacza liczbę mnogą, np. buk ‘książka’ – ol buk ‘książki’. Przykłady na liczbę mnogą w tok pisin znajdziemy także w nazwie Powszechnej Deklaracji Praw Człowieka w tym języku: ol raits bilong ol manmeri dosł. „prawa ludzi” = ‘prawa człowieka’. Słowa wyrażające pojęcia takie jak ‘człowiek’, ‘prawa’, ‘deklarować’, ‘mówić’, ‘powszechny’ nazywane są wyrazami znaczącymi.
Z grubsza rzecz ujmując, istnieją dwa sposoby wyrażania znaczenia gramatycznego: przy użyciu wyrazów funkcyjnych (ol, bilong w tok pisin, angielskie the, of itp.) lub poprzez odmianę wyrazów znaczących, tj. zmianę ich formy przez np. dodanie lub obcięcie końcówki. Polski i węgierski to przykłady języków, które stosują głównie odmianę.
| ‘Powszechna deklaracja praw człowieka’ | |
| polski | Powszechna deklaracja praw człowieka |
| węgierski | Az emberi jogok egyetemes nyilatkozata |
Przykład z języka polskiego zawiera wyrazy znaczące (powszechny, deklaracja, prawo, człowiek), każdy w odmienionej formie ukazującej jego funkcję i związek z innymi słowami w ramach całego wyrażenia. Ostatni wyraz (człowieka) jest formą dopełniacza liczby pojedynczej wyrazu człowiek, utworzoną przez dodanie końcówki -a do formy podstawowej. Praw jest formą dopełniacza liczby mnogiej wyrazu prawo – forma podstawowa tego wyrazu ma końcówkę (praw-o), podczas gdy dopełniacz liczby mnogiej nie. Po polsku fraza praw człowieka odpowiada niderlandzkiemu van de rechten van de mens.
W wersji węgierskiej znajdujemy jeden wyraz funkcyjny (rodzajnik określony az) i cztery wyrazy znaczące: (‘człowiek’, ‘prawa’, ‘powszechny’, ‘deklaracja’). Liczbę mnogą oznacza się sufiksem dołączonym do rzeczownika: jog-ok ‘prawa’ (jog ‘prawo’). Relacja pomiędzy wyrazami ‘deklaracja’ i ‘prawa człowieka’ oznaczona jest sufiksem -a w wyrazie nyilakozat-a ‘deklaracja’.
(Zob. sekcja Jak wyrażać posiadanie, poniżej)
Zadanie
Porównaj tłumaczenia Powszechnej Deklaracji Praw Człowieka i znajdź w nich wyrazy funkcyjne.
Wyrazy w języku mówionym
W tekstach pisanych współczesnymi alfabetami słowo można łatwo zdefiniować: słowo to ciąg liter oddzielonych od siebie spacjami czy znakami interpunkcyjnymi. Tego rodzaju wyraz to ściślej wyraz graficzny. Wątpliwości pojawiają się np. przy angielskich I’m (= I am), I’ve (= I have) czy he’s (= he is). W mowie tego rodzaju wątpliwych przypadków może być więcej niż tych jednoznacznych, a wyraźne granice między słowami mówionymi wyznaczyć jest dużo trudniej. Określenie, co należy zapisywać za pomocą jednego wyrazu graficznego, a co oddzielnie, okazuje się jednym z najtrudniejszych wyzwań w procesie tworzenia ortografii dla języków wcześniej nie zapisywanych (zob. rozdział 5: Pismo), a i w językach posiadających tradycję piśmienniczą zasady ortografii bywają często przedmiotem sporu. Pojęcie wyrazu oraz różnice pomiędzy wyrazami funkcyjnymi a odmianą to idealizacje działające najlepiej na przykładzie języka pisanego.
Zadanie
Znajdź w języku polskim (lub w innym języku, który dobrze znasz) przykłady niejasnych granic między słowami.
Wyrazy funkcyjne są często krótkie i słabo akcentowane, dlatego też mają one tendencję do zlewania się z wyrazami sąsiednimi. Elementy w ten sposób łączące się ze słowem bez jednoczesnego stawania się jego częścią nazywamy klitykami. Przykładami klityk w języku angielskim są: <’s>, <’ve> i <‘m>. Klityki różnią się od sufiksów (przyrostków) tym, że mogą być dołączane do różnych wyrazów – sufiksy przeważnie dołącza się do wyrazów należących do jednej kategorii części mowy (czasownika, rzeczownika czy przymiotnika) i mają stałe miejsce, jakkolwiek ostrych granic w zasadzie nie ma. Wyrazy funkcyjne mogą z czasem stać się klitykami (np. angielskie <am> staje się <’m>), a klityki – sufiksami. Zastanów się nad poniższym przykładem z języka polskiego:
(W sekcji Jak pokazywać strukturę wyrazów i zdań znajdziesz informacje na temat techniki oznaczania znaczeń gramatycznych użytej w tym i następnych przykładach, a także wyjaśnienia skrótów.)
śpiewa-ł-a=by
sing-PST-F-COND
gdy=by śpiewa-ł-a
if-COND sing-PST-F
(PST = czas przeszły, F = rodzaj żenski, COND = tryb warunkowy)
Wyznaczniki czasu przeszłego -ł- oraz rodzaju żeńskiego -a- mają stałe miejsce w ramach formy czasownika, podczas gdy oznaczające tryb przypuszczający -by można dołączać zarówno do czasownika, jak i do spójnika. Dawniej -by było wyrazem funkcyjnym, a teraz stanowi klitykę, która jest na drodze do stania się sufiksem.
Wewnętrzna struktura wyrazów
Wyrazy mogą zawierać wiele komponentów. Najmniejsze elementy wyrazu niosące znaczenie to morfemy. Pod „znaczeniem” rozumiemy tutaj również znaczenie gramatyczne. Na przykład wyraz człowieka zawiera dwa morfemy: rdzeń człowiek oraz końcówkę dopełniacza -a. Wyraz niepowtarzalny zawiera cztery elementy znaczeniowe (morfemy): wyrażający negację prefiks nie- , rdzeń powtarz-, sufiks przymiotnikowy -aln- oraz końcówkę -y. Jeden morfem może przybierać różne postaci. -aln-, -eln- (np. w wyrazie czyt-eln-y) czy też -n- (np. przejezd-n-y) to formy tego samego morfemu, używanego do tworzenia przymiotników od czasowników. Konkretna manifestacja morfemu w języku mówionym bądź pisanym to morf. Byłoby zatem trafniej powiedzieć, że forma wyrazowa <prawa> zawiera dwa morfemy reprezentowane przez dwa morfy: <praw> i <a>. Kiedy morfem ma kilka postaci, nazywane są one alomorfami. Morfy <aln>, <eln> i <n> są alomorfami tego samego morfemu. Z drugiej strony, <n> w <przejezd-n-y> i <n> w <szkol-n-y> są morfami należącymi do różnych morfemów, gdyż wyrażają odmienne znaczenia: pierwszy reprezentuje morfem przymiotnikowy dołączany do rdzenia czasownikowego i wyraża „możliwość, zdolność”, natomiast w drugim przypadku również chodzi o morfem przymiotnikowy, ale dołączany jest on do rdzenia rzeczownikowego i niesie znaczenie „związany z przedmiotem oznaczanym przez rzeczownik”.
| Wyróżniamy następujące typy elementów składających się na wyraz: | |
| rdzeń | morfem niosący znaczenie leksykalne (praw-a, nie-powtarz-aln-y) |
| sufiks | morfem następujący po rdzeniu (praw-a, niepowtarz-aln-y) |
| prefiks | morfem poprzedzający rdzeń (nie-powtarzalny) |
| afiks | termin zbiorczy obejmujący prefiks, sufiks itd. (zobacz poniżej) |
| końcówka | ostatni sufiks wyrażający znaczenie gramatyczne (praw-a, niepowtarzaln-y) |
| temat | część wyrazu, do której dołącza się końcówkę, jeśli taka jest; temat może zawierać sam rdzeń (praw-), rdzeń oraz jeden lub więcej afiksów (niepowtarzaln-) bądź jeden lub więcej rdzeni, z afiksami lub bez (niemieckie Menschenrecht-, estońskie inimõigus-) |
Słowotwórstwo
Słowo słowo jest niejednoznaczne: może odnosić się do formy będącej częścią tekstu mówionego lub pisanego (np. gdy liczymy ilość słów w tekście) albo do bardziej abstrakcyjnej jednostki znaczeniowej (np. gdy mówimy, że <prawo> i <prawa> to formy tego samego wyrazu). Techniczną nazwą dla „słowa” w tym drugim znaczeniu jest leksem, a to, co widzimy w tekście, to formy wyrazowe. Tworzenie form wyrazowych należących do jednego leksemu nazywa się fleksją, a tworzenie nowych leksemów – słowotwórstwem.
Jedną z metod budowania słów (leksemów) jest tworzenie wyrazów złożonych. Jest to kombinacja dwóch (a czasem więcej) rdzeni tworzących jeden wyraz. Powyżej mieliśmy przykłady z języka niemieckiego (Menschenrechte) i estońskiego (inimõigused) znaczące ‘prawa człowieka’. Wyrazy złożone można znaleźć też w przykładzie z języka tok pisin: toksave ‘deklaracja’ zawiera rdzenie tok ‘mówić’ i save ‘wiedzieć’; manmeri ‘ludzie’ składa się z man ‘mężczyzna’ i meri ‘kobieta’. Poniżej znajdziesz przykłady z innych języków:
| język | wyraz słożony | znaczenie | części składowe |
| teop [3] | beiko moon | ‘dziewczyna’ | beiko ‘dziecko’ + moon ‘kobieta’ |
| logba [4] | iwónɖú | ‘miód’ | iwó ‘pszczola’ + nɖú ‘woda’ |
| sheko [5] | bōw kuʈʂu | ‘dłon’ | bōw ‘brzuch’ + kúʈʂú ‘ręka’ |
| yārb suku | ‘żyła’ | yārbm̄ ‘krew’ + súkú ‘lina’ | |
| ʂūbū bambù | ‘grób’ | ʂūbū ‘śmierć’ + bambù ‘rów’ |
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenia z wyrazami złożonymi w języku wilamowskim.
W wielu językach wyrazy (leksemy) buduje się poprzez dodanie przyrostków bądź przedrostków do rdzenia lub tematu wyrazu. Taki rodzaj tworzenia słów nazywa się derywacją. Na przykład:
| węgierski | ember ‘człowiek’ (rzeczownik) -> ember-i ‘ludzki’ (przymiotnik) |
| polski | prawo (rdzeń praw--> praw-nik |
| niderlandzki | verklar- ‘deklarować’ (temat czasownikowy) -> verklar-ing ‘deklaracja’ (rzeczownik) |
Więcej przykładów i innych technik tworzenia nowych słów znajdziesz w dalszej części tego rozdziału.
Słowotwórstwo może być “skrótem” do oddania znaczenia, które inaczej trzeba byłoby wyrazić przy użyciu kilku słów. Na przykład w języku czoktaw znaczenie wyrazu tononoli, który został wyderywowany od tonoli ’kołysać się’, po polsku da się oddać za pomocą wyrażenia „kołysać się w przód i w tył”. Z drugiej strony, w tekście Powszechnej Deklaracji Praw Człowieka w języku tok pisin znajdujemy znaczenie ‘powszechny’ oddane jako long olgeta hap bilong dispel giraun ‘we wszystkich miejscach na tym świecie’.
Techniki budowania wyrazów i form wyrazowych
We fleksji i derywacji stosowanych jest wiele środków formalnych. Najbardziej rozpowszechnione jest używanie afiksów (zrostków), w szczególności sufiksów (przyrostków) – elementów stojących za rdzeniem – oraz prefiksów (przedrostków), które rdzeń poprzedzają. Na przykład:
| język | podstawa słowotwórcza | formy z sufiksami, prefiksami lub jednymi i drugimi |
|
sheko [6] |
íík’ ‘być starym’ (czasownik) sūb ‘być czerwonym’ (czasownym) ʒááʒ ‘być dobrym’ (czasownik) |
ííkńs‘stary’ (przymiotnik) sūbm̄s‘czerwony’ (przymiotnik) ʒééǹʃ ‘dobry’ (przymiotnik) |
|
khim ‘dom’ |
uƞkhim ‘mój dom’, kakhim ‘twój dom’ |
|
|
logba [8] |
gbla ‘uczyć’ zɔ ‘przedawać’ |
ɔgblawo ‘nauczyciel’ ɔzɔwo ‘przedawca’ uwaga: ɔ- jest prefiksem a -wo sufiksem |
Innym typem afiksu jest infix (wrostek), który umieszcza się wewnątrz rdzenia, na przykład:
| język | podstawa słowotwórcza | formy z infiksami |
|
peelh ‘zamiatać podłogę’ tɛk ‘uderzać’ chrɛɛt ‘czesać’ |
prneelh ‘miotła’ trnɛk ‘młotek’ chnrɛɛt ‘grzebień’ |
|
|
|
máni ‘on śpiewa’ aphé ‘on uderza’ hoxpé ‘on kaszlę’ |
mawáni ‘ja śpiewam’ awáphe ‘ja uderzam’ howáxpe ‘ja kaszlę’ |
Podczas gdy infiks rozdziela podstawę słowotwórczą, transfiks (zwany też konfiksem) sam w sobie jest podzielony na części, które umieszcza się w rdzeniu. Tego rodzaju proces morfologiczny można spotkać w językach semickich (arabskim, hebrajskim). Różne sekwencje samogłosek są umieszczane w rdzeniach spółgłoskowych, do których czasem dołącza się sufiks. Na przykład w dialekcie egipskim języka arabskiego rdzeń oznaczający ‘pisać’ to k-t-b, a przykładami form tego wyrazu będą: katab ‘on napisał’, ki’taab ‘książka’, mak’taba ‘księgarnia’, mak’tuub ‘napisany’ (Bauer 1988: 25).
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenia z afiksami w języku yeri.
Reduplikacja to powtarzanie słów lub ich części. Technika ta jest bardzo rozpowszechniona w językach świata. W Europie jest dość rzadka, ale spotykana: na przykład w łacinie niektóre czasowniki tworzą formy czasu Perfekt poprzez reduplikację pierwszej części rdzenia. Reduplikowane mogą być też środkowe lub końcowe partie wyrazu, tak jak w poniższych przykładach z języka czoktaw. Dane pochodzące z języków z całego świata zebrane są w Graz Database on Reduplication, która jest dostępna online. Więcej informacji na temat reduplikacji w językach świata możesz znaleźć w World Atlas of Language Structures (Rubino 2013).
| język | forma bez reduplikacji | form z reduplikacją |
| łaciński | curr-o ‘biegnę’ tend-o ‘naciągam’ pung-o ‘kłuję’ |
cucurr-i ‘biegłam/-em’ tetend-i ‘naciągnęłam/-ąłem’ pupung-i ‘ukłułam/-em’ |
| czoktaw [11] | tonoli ‘kołysać się’ binili ‘siedzieć’ |
tononoli ‘kołysać się w przód i w tył’ bininili ‘podnieść się i usiąść’ |
| amele [12] | ana ‘gdzie’ me ‘dobry’ ʔela ‘długi’ dahing ‘uszy’ eben ‘ręce’ gasuena ‘on szuka’ |
anaana ‘gdziekolwiek’ meme ‘bardzo dobry’ ʔeʔela ‘bardzo długi’ dadahing ‘uszy wszystkich’ ebeben ‘ręce wszystkich’ gasu-gisu-ena ‘on szuka nieustannie’ |
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenia z reduplikacją w językach teop i totoli.
Inną techniką stosowaną we fleksji i derywacji jest modyfikowanie rdzenia. Tego typu zjawiskami są na przykład:
-
ablaut (apofonia) – wymiana samogłoski w ramach rdzenia, np. angielskie man – men, sing – sung, sing – song;
-
alternacja spółgłoskowa na początku lub końcu rdzenia, np. w języku angielskim believe ‘wierzyć’ – belief ‘wiara’. Alternacje spółgłoskowe zachodzące na początku rdzenia są typowe dla języków celtyckich, np. w języku walijskim cartref ‘dom’ – gartref ‘w domu’;
- zmiana akcentu: angielskie ‘import ‘import’ – im’port ‘importować’;
-
zmiana tonu w językach tonalnych. Popatrz na przykłady z języków logba i sheko, w których tony (zaznaczane w piśmie akcentami) są wykładnikami kategorii gramatycznych takich jak czas czy osoba:
| język | przykład | |
| logba [13] | Matúkpí ubón adzísiadzí. Matukpí ubón adzísiadzí. |
‘Chodziłam na farmę codziennie.’ ‘Chodzę na farmę codziennie.’ |
| sheko [14] | Ṃbaadúra hadùfù. Ḿbaadúra hádùfù. |
‘Czy uderzyłeś mojego młodszego brata?’ ‘Czy on uderzył naszego młodszego brata?’ |
Różne techniki można ze sobą łączyć, na przykład sufiksację z alternacją spółgłoskową i alternacją samogłoskową. W języku polskim mianownik liczby pojedynczej wyrazu las wymawiany jest [las]. Forma miejscownika tworzona jest poprzez dodanie sufiksu -e, wymianę samogłoski [a] na [ɛ] oraz ostatniej spółgłoski [s] na [ɕ]: w lesie [lɛɕɛ].
Kategorie gramatyczne
Wyrazów funkcyjnych, afiksów i innych technik tworzenia form wyrazowych opisanych powyżej używa się do wyrażenia kategorii gramatycznych, takich jak liczba (pojedyncza, mnoga), czas (przeszły, teraźniejszy, przyszły) czy przypadek (mianownik, biernik, celownik). Jedną z charakterystycznych cech kategorii gramatycznych jest ich obowiązkowe użycie w danym języku. Na przykład w wielu językach europejskich wyrazy obowiązkowo przybierają jakąś cechę pod względem liczby: mówimy albo o książce, albo o książkach. Z kolei w wielu językach z Australii czy Ameryki Północnej rzeczowniki nie różnią się pod względem liczby, lub tylko niektóre z nich mają tę cechę. Na przykład w australijskim języku warrgamay ƞulmburru może znaczyć ‘kobieta’ lub ‘kobiety’ (Corbett 2001: 84, za: Dixon 1980).
Innym przykładem kategorii obowiązkowej tylko w pewnych językach jest określoność. Jeśli chcemy przetłumaczyć na angielski zdanie Kupiłam książkę, musimy się zdecydować na I bought a book albo I bought the book. To pokazuje, że w języku angielskim określoność jest kategorią gramatyczną, ale w języku polskim nie jest. Można co prawda po polsku powiedzieć Kupiłam tę książkę czy Kupiłam jakąś książkę, ale nie będzie to to samo, co regularny i obowiązkowy wybór pomiędzy rodzajnikiem określonym a nieokreślonym w językach takich jak angielski czy niemiecki. Zdanie o kupowaniu książki w języku polskim mówi nam, że osobą kupującą jest kobieta – mężczyzna powiedziałby oczywiście Kupiłem książkę. Rodzaj (męski, żeński, nijaki) jest bowiem w języku polskim kategorią gramatyczną, która musi być oznaczana na formach czasowników w czasie przeszłym (jak również i na przymiotnikach oraz zaimkach), podczas gdy w języku angielskim rodzaj nie stanowi kategorii gramatycznej. Jeśli chcemy przetłumaczyć z angielskiego na polski zdanie I bought a book, by stworzyć formę czasownika musimy wpierw wiedzieć, czy osoba mówiąca jest mężczyzną, czy kobietą. Wybór pomiędzy -a- i -e- w szkielecie kupił_m musi być dokonany – jest obowiązkowy. W języku angielskim rodzaj jest ważny tylko dla zaimków trzeciej osoby: He bought books vs. She bought books. Z kolei węgierski w ogóle nie wprowadza takiego rozróżnienia, a oba angielskie zdania tłumaczy się na ten język jako (ö) vett könyveket: ö może znaczyć zarówno ‘ona’, jak i ‘on’ (użycie zaimka ö nie jest w tym zdaniu obowiązkowe).
Inwentarz kategorii gramatycznych, z których języki mogą wybierać, jest bardzo bogaty. Niemniej jednak te same kategorie spotykamy w językach z całego świata. Najbardziej rozpowszechnione są: osoba, liczba, rodzaj, określoność, przypadek, czas, aspekt (np. dokonany, niedokonany, ciągły), tryb (np. rozkazujący, warunkowy), strona (np. czynna, bierna) oraz inne, nieznane językom europejskim kategorie. Dla każdej z nich istnieje skończona liczba opcji. Na przykład jeśli weźmiemy kategorię liczby, większość języków rozróżnia liczbę pojedynczą (jeden) i mnogą (więcej niż jeden), ale niektóre wyróżniają więcej cech: liczba pojedyncza (jeden) – podwójna (dwa) – mnoga (więcej niż dwa), lub: pojedyncza (jeden) – paukalis (kilka) – mnoga (wiele).
Teraz przyjrzymy się uważniej dwóm z tych kategorii: osobie i rodzajowi.
Osoba
Kategoria osoby związana jest z uczestnikami aktu mowy. Formalnie wyznaczana jest przez zaimki osobowe (ja, ty, my) i/lub formy osobowe czasowników, np. w języku polskim kocham, kochasz, kochamy itd. Przeważnie spotykamy podział kategorii osoby na trzy: pierwszą osobę = osobę mówiącą (ja), drugą osobę = adresata (ty) i trzecią osobę = inne osoby lub rzeczy nie biorące udziału w akcie mowy (ona, to, oni itp.). Ten system jest często połączony z systemem liczby wyróżniającym cechę pojedynczości i mnogości, tak że np. ‘my’ jest definiowane jako pierwsza osoba liczby mnogiej. Nie jest to jednak precyzyjna definicja w tym sensie, że my nie jest formą liczby mnogiej od ja tak samo, jak drzewa od drzewo. My przeważnie nie odnosi do kilku mówiących, a do kombinacji mówiącego z kimś innym, drugą osobą lub trzecią. W języku polskim pytanie Czy spotkamy się jeszcze? może oznaczać Czy ty i ja się jeszcze spotkamy? albo na przykład Czy ona i ja się jeszcze spotkamy?, w zależności od kontekstu, w którym jest wypowiadane. Pierwsze ze znaczeń nazywane jest inkluzywnym (ponieważ zawiera się w nim osoba będąca adresatem wypowiedzi), a drugie ekskluzywnym. Wiele języków rozróżnia te znaczenia przy użyciu odrębnych zaimków. Na przykład w języku czamorro [15] są dwa wyrazy oznaczające ‘my’: ta (inkluzywne, tzn. ‘ty i ja’) oraz in (ekskluzywne, ‘ja i on/ona). Więcej na temat tego rozróżnienia znajdziesz w rozdziałach: 39 i 40 WALS (Cysouw 2013a, 2013b).
Jeśli rozróżnienie na ‘my’ inkluzywne i ekskluzywne połączyć z rozróżnieniem w obrębie liczby na pojedynczą, podwójną i mnogą, kombinacji znaczeń znajdzie się dużo więcej. Porównaj zdania z języka puma [16]. Są różne sposoby powiedzenia „jemy ryż”, w zależności od tego, czy mówimy o osobie, do której się zwracamy, oraz czy chodzi o dwie, czy więcej osób:
| ‘jemy ryż’ | ‘my’ = | category label |
|
keci roƞ caci |
‘ty i ja’ |
liczba podwójna inkluzywna |
|
ke roƞ cee |
‘ty, ja i przynajmniej jedna inna osoba’ |
liczba mnoga inkluzywna |
|
kecika roƞ cacika |
‘on/ona i ja’ |
liczba podwójna ekskluzywna |
|
keka roƞ ceeka |
‘oni i ja’ |
liczba mnoga ekskluzywna |
*Uwaga: pierwszy wyraz jest zaimkiem osobowym (‘my’), a ostatni czasownikiem ‘jeść’ odmienionym przez osoby.
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenia 4 z języka daakaka (Vanuatu).
Rodzaj (klasa rzeczownika)
W językach europejskich przeważnie rozróżnia się rodzaj męski i żeński albo męski, żeński i nijaki. W innych rejonach świata można spotkać języki wyróżniające cztery czy pięć rodzajów. Język fula z Nigerii ma ich aż 20. Z kolei część języków w ogóle nie rozróżnia rodzajów. W World Atlas of Language Structures (Corbett 2013) znajdziemy następującą informację: W próbce 257 języków z całego świata, 145 nie wyróżniało rodzaju jako kategorii gramatycznej (tak jak angielski i węgierski), 50 miało dwa rodzaje (w Europie taka sytuacja ma miejsce np. we francuskim i łotewskim), w 26 językach były trzy rodzaje (jak w niemieckim czy polskim), w 12 cztery, a w 24 – pięć lub więcej. Języki z pięcioma i więcej klasami najczęściej znajdziemy w Afryce, ale też w Australii i Papui-Nowej Gwinei.
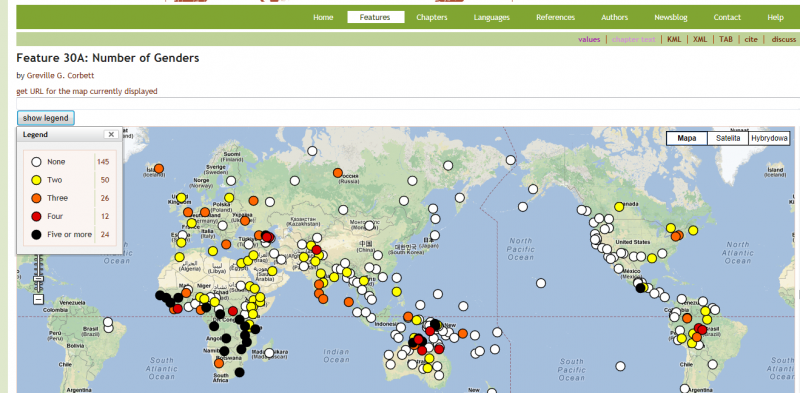 Liczba klas rzeczownika (rodzajów) w różnych językach świata (WALS, Corbett 2013) |
“Idea” rodzaju gramatycznego polega na grupowaniu rzeczowników w różne klasy, co odzwierciedla związek zgody pomiędzy formą danego rzeczownika oraz innych wyrazów w ramach tej samej frazy lub zdania. Dzielenie rzeczowników na tego rodzaju klasy (rodzaje) może być umotywowane semantycznie, na przykład rzeczowniki oznaczające istoty ludzkie mogą należeć do jednej klasy, a te oznaczające drzewa – do innej itd. Tradycyjne nazwy takie jak „rodzaj”, „męski”, „żeński” pochodzą z języków europejskich, w których rzeczowniki oznaczające istoty ludzkie i niektóre zwierzęta należą do różnych klas w zależności od płci osoby czy obiektu oznaczanego (np. wyraz na ‘mężczyzna’ jest rodzaju męskiego, a ‘kobieta’ – żeńskiego). Przyporządkowywanie większości rzeczowników do określonych klas nie ma jednak motywacji semantycznej, a jest to klasyfikacja czysto gramatyczna. Na przykład w języku polskim książka należy do rodzaju żeńskiego, podczas gdy czasopismo jest rodzaju nijakiego, a artykuł – męskiego. Poniższe zdania pokazują związek zgody zachodzącą pomiędzy przymiotnikami, zaimkami i niektórymi z form czasownikowych a odpowiednim rzeczownikiem:
Ten dobr-y artykuł został wydan-y już dawno.
Ta dobr-a książka został-a wydan-a już dawno.
To dobr-e czasopismo został-o wydan-e już dawno.
Termin “klasa rzeczownika” jest bardziej neutralny od terminu „rodzaj”, ponieważ stosując go unika się skojarzeń z płcią. Poszczególne klasy mogą być po prostu oznaczone jako „klasa 1”, „klasa 2” i tak dalej. Poniższe przykłady pochodzą z języka yimas [17], który ma 10 klas. Sufiksy dołączane do wyrazów ‘mój’ i ‘duży’ pokazują, że słowa ‘stopa’, ‘kosz’ i ‘głos’ należą do różnych klas, tak jak polskie wyrazy: artykuł, książka i czasopismo:
| namtampara | amana | kpa | ‘moja duża stopa’ |
| stopa | mój:class9.sg | duży:class9.sg | |
| antuk | amana-w? | kpa- w? | ‘mój donośny głos’ |
| głos | mój-class10.sg | duży-class10.sg | |
| impran | amana-m | kpa-m | ‘mój duży kosz’ |
| kosz | mój-class7.sg | duzy-class7.sg |
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenie dot. klas rzeczownika w języku logba z Ghany.
Klasyfikatory
Innym narzędziem grupowania rzeczowników widocznym w gramatyce języka są klasyfikatory. Są to wyrazy funkcyjne używane w ramach pewnych struktur razem z rzeczownikami. Typowymi konstrukcjami zawierającymi klasyfikatory są wyrażenia liczebnikowe, takie jak w poniższych przykładach z języka minangkabau [18] używanego w Indonezji:
| sar-urang jeden-CLF |
padusi kobieta |
‘jedna kobieta’ | |
| duo dwa |
ikue CLF |
anjiang pies |
‘dwa psy’ |
| tigo trzy |
batang CLF |
pituluik ołówek |
‘trzy ołówki’ |
Moglibyśmy sparafrazować te przykłady jako „jedna osoba kobieta”, „dwa zwierzę pies” i „trzy rzecz ołówek”, jednak musimy pamiętać, że wyrazy urang, ikue, batang są w języku minangkabau wyrazami funkcyjnymi, a nie rzeczownikami.
Wiele języków Ameryki Północnej używa klasyfikatorów, które odnoszą się do dopełnienia czasownika. W takich językach np. czasownik oznaczający ‘dawać’ będzie miał różne formy w zależności od tego, co jest dawane. W poniższych przykładach z języka czirokeskiego [19] klasyfikator umieszczany jest wewnątrz sekwencji gà-____-nèè’a, która oznacza ‘ona daje mu’. Pierwsze słowa czirokeskich zdań znaczą, odpowiednio: ‘kot’, ‘woda’ i ‘koszula’:
| Wèésa | gà-káà-nèè’a | ‘Ona daje mu kota’ (káàdla istot żywych) |
|
Àma |
à-nèèh-nèè’a | ‘Ona daje mu wody’ (nèèh dla płynów) |
| Àhnàwo | gà-nʊ́ʊ́-nèè’a | ‘Ona daje mu koszulę’ (nʊ́ʊ́ dla rzeczy giętkich) |
Szyk wyrazów
Dla większości języków istotna jest kolejność pojawiania się wyrazów w zdaniu: może istnieć tylko jedna dopuszczalna kombinacja albo różne szyki, które mogą nieść inne znaczenia. Język angielski jest bardzo restrykcyjny jeśli chodzi o szyk zdania i w zdaniach przechodnich (z dopełnieniem) zezwala tylko na sekwencję podmiot – orzeczenie – dopełnienie. Po angielsku możemy na przykład powiedzieć jedynie He loves me, ale nie: *Loves he me, *Me loves he, *He me loves [20] itd. W niemieckim najważniejszą zasadą w prostych zdaniach oznajmujących jest występowanie orzeczenia na drugiej pozycji. Zarówno Er liebt mich, jak i Mich liebt er są gramatycznie poprawnymi zdaniami języka niemieckiego. Jeśli poszerzymy to zdanie o dodatkowe słowo, dajmy na to vielleicht ‘może’, poprawne będą: Vielleicht liebt er mich ‘może on mnie kocha’, Er liebt mich vielleicht oraz Mich liebt er vielleicht, ale *Vielleicht er liebt mich, z orzeczeniem na trzeciej pozycji, już nie. Różnica pomiędzy niemieckimi zdaniami Er liebt mich i Mich liebt er polega na tym, że w drugim wyróżnia się dopełnienie, podczas gdy w pierwszym jest ono neutralne. Wiele języków wykorzystuje szyk zdania aby coś wyróżnić, przeważnie odbywa się to z udziałem odpowiedniej intonacji. Jeśli zmiana kolejności słów nie jest w jakimś języku dozwolona, mogą istnieć specjalne konstrukcje pozwalające umieścić dopełnienie na początku zdania, np. w angielskim It’s me he loves albo I am the one he loves. Najbardziej neutralna kolejność wyrazów jest nazywana „podstawowym szykiem zdania”.
Badając podstawowe szyki zdania w różnych językach, lingwiści odkrywają pewne prawidłowości. Dla zdań prostych z trzema elementami: podmiot (S), dopełnienie (O) i orzeczenie (V) istnieje sześć możliwych kombinacji pojawiania się tych elementów: SOV, SVO, OSV, OVS, VSO, VOS. Jeśli wybór byłby kompletnie przypadkowy, moglibyśmy zakładać, że każdy z tych schematów pojawiałby się w językach świata z mniej-więcej równą częstotliwością. Tak jednak nie jest. Szyk z podmiotem na pierwszym miejscu spotykamy bowiem dużo częściej, niż inne. Poniżej mamy rezultaty badań nad szykiem w 1377 językach (Dryer 2013a; pod linkiem znajdziesz więcej informacji na temat szyku oraz przykłady zdań):
| podstawowy szyk zdania | przykłady języków | liczba języków |
| SOV | turecki, saliba [21] |
565 |
| SVO | francuski, lelemi [22] |
488 |
| VSO | walijski, maoryjski [23] |
95 |
| VOS | malgaski [24] tsotsil [25] |
25 |
| OVS | hixkaryana [26] |
11 |
| OSV | nadëb [27] |
4 |
| brak dominującego szyku | węgierski, nunggubuyu [28] |
189 |
| razem |
1377 |
Na podstawie tych danych możemy wysnuć wniosek, że języki mają wyraźną tendencję do umieszczania podmiotu przed dopełnieniem – tylko w 40 z 1377 badanych języków dopełnienie poprzedza podmiot w zdaniach o szyku podstawowym. Dodajmy, że badanie, o którym mowa, dotyczyło jedynie zdań z podmiotami i dopełnieniami nominalnymi, (tzn. typu Kot gonił ptaka), a nie wyrażanymi za pomocą zaimków (On gonił go) lub końcówek osobowych czasownika (Goniłem go).
Pytania do rozstrzygnięcia
Kolejną funkcją szyku zdania w języku niemieckim jest rozróżnienie zdań oznajmujących od pytających, a dokładniej takich, na które można odpowiedzieć „tak” lub „nie”. Podczas gdy w zdaniach oznajmujących czasownik jest na drugiej pozycji, w tego typu pytaniach umieszcza się go na pierwszym miejscu, po czym przeważnie następuje podmiot: Liebt er mich? ‘Czy on mnie kocha?’, Liebt er mich vielleicht? ‘Czy on mnie może kocha?’, Liebt er vielleicht mich? ‘Czy to może mnie on kocha?’. Taką technikę tworzenia pytań znajdziemy głównie w językach europejskich (niemieckim, niderlandzkim, szwedzkim, czeskim, hiszpańskim i in.), z rzadka w językach używanych w innych częściach świata. Różne strategie używane do tworzenia pytań tak/nie i ich występowanie w językach świata opisane są w rozdziale 116 WALS (Dryer 2013b).
Najpopularniejszą techniką formowania pytań w językach z całego globu jest stosowanie partykuły pytajnej, takiej jak polskie czy. W języku polskim, tak jak i w wielu innych językach, partykuła pytajna stoi na początku zdania, w niektórych na końcu, a w części języków umieszczana jest po pierwszym wyrazie w zdaniu.
| język | przykład | |
| polski | Jan kupił książki.
Czy Jan kupił książki? |
|
| maybrat [29] | ana m-amao Kumurkek a 3PL 3-iść Kumurkek Q |
‘Czy oni idą do Kumurkek??’ |
| mono [30] | Charley=w̃aʔ mia-pɨ Charley=Q iść-PERF |
‘Czy Charley już wyszedł?’ (pytanie oznaczamy klityką dołączaną do pierwszego wyrazu) |
3 = trzecia osoba, PL = liczba mnoga, Q = partykuła pytajna, PERF = czas perfekt
Część języków zaznacza pytanie przy pomocy formy czasownika. W takim przypadku często spotyka się specjalną formę fleksyjną stosowaną do formułowania pytań, podczas gdy w zdaniach oznajmujących czasownik pozostaje nieodmieniony. W niektórych językach spotykamy odwrotny układ: zdania oznajmujące obowiązkowo zawierają morfem, którego brakuje zdaniom pytającym. Przykłady poniżej pochodzą z dwóch języków używanych w Etiopii:
| język | przykład | |
| zayse [31] |
hamá-tte-ten háma-ten |
‘Pójdę’ ‘Czy pójdę?’ |
| sheko [32] |
ṇ-māāk-ā-m ṇ-māāk-ā únà ʂókú tuurùk’à tʂ’ádǹ kìákɘ únà ʂókú tuurùk’à tʂ’ádǹ kìa |
‘Powiem’ ‘Czy powiem?’ ‘W przeszłości była wojna w Sheko.’ ‘Czy w przeszłości była wojna w Sheko?’ |
Intonacja pytań różni się w większości języków od intonacji zdań oznajmujących. Niekiedy intonacja jest jedyną cechą odróżniającą zdania pytające od oznajmujących.
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenie 1 z języka ǂakhoe.
Jak wyrażać posiadanie
Sposobów na oddanie tego samego znaczenia może być kilka nawet w ramach jednego języka. Dobrym przykładem ilustrującym to zjawisko jest posiadanie, tzn. znaczenie „ktoś ma coś”, „coś należy do kogoś”. Na przykład po polsku możemy powiedzieć Ona ma czarne włosy, Jej włosy są czarne, Ona jest czarnowłosa. Inwentarz możliwości jest różny w zależności od przedmiotu posiadanego: nie możemy powiedzieć *Ona jest czarnosamochodowa, by oddać to samo znaczenie, co Ona ma czarny samochód. Z kolei *Ona posiada czarne włosy nie będzie zdaniem poprawnym, ale Ona posiada czarny samochód już tak. W większości języków zachodniej Europy, w tym w polskim, konstrukcja z czasownikiem ‘mieć’ jest najbardziej podstawowa; używa się jej do wyrażania różnych typów relacji posiadania (Mam samochód / Mam brata / Mam czas / Mam dwadzieścia lat...).
| Terminologia | |
| posiadanie | relacja pomiędzy posiadaczem a przedmiotem posiadanym, znaczenie ‘mieć’, ‘posiadać’, ‘należeć’ |
| posiadacz (possessor) | ktoś lub coś, co coś posiada, w zdaniach: Jan ma czarne włosy, Jan posiada dwa domy, Ten samochód należy do Jana oraz w wyrażeniu ojciec Jana, imię Jan oznacza posiadacza |
| przedmiot posiadany (possessum) | to, co do kogoś lub czegoś należy; w zdaniach: Zuzia ma samochód, Ten samochód należy do Marysi, Samochód mojej matki jest czerwony, przedmiotem posiadanym jest samochód |
W języku grenlandzkim czasownik ‘mieć’ oraz rzeczownik oznaczający przedmiot posiadany tworzą razem czasownik złożony:
| język | przykład | |
| grenlandzki [33] | angut taanna qimmi-qar-puq człowiek ten pieś-mieć-3SG.IND |
‘Ten człowiek ma psy’, dosłownie: “Ten człowiek psy-ma” |
3 = trzecia osoba, SG = liczba pojedyncza, IND = tryb orzekający
W konstrukcjach z czasownikiem ‘mieć’ posiadacz jest podmiotem zdania. Większość języków świata używa jednak innych strategii wyrażania posiadania. W próbce 240 języków tylko 63 miało odpowiednik polskiego czasownika mieć, wiele z nich to języki środkowej i zachodniej Europy (Stassen 2013, rozdział 117 WALS). Języki nie posiadające czasownika ‘mieć’ przeważnie stosują konstrukcje z czasownikiem znaczącym ‘być’. Typ ‘być’ jest w językach świata bardziej rozpowszechniony, niż typ ‘mieć’. W typie ‘być’ to przedmiot posiadany często pełni funkcję podmiotu w zdaniu, a czasownik wyraża istnienie lub położenie. Posiadacza wyraża się w takich językach na różne sposoby: na przykład formą celownika, tak jak w węgierskim i sheko, czy też za pomocą przyimka – takiej strategii używa język irlandzki. W innych językach znaczenie ‘Mam samochód’ wyraża się za pomocą konstrukcji, które dosłownie przetłumaczylibyśmy jako „samochód jest ze mną”, „mój samochód istnieje” czy choćby „jeśli chodzi o mnie, to jest samochód”.
| język | przykład | |
| węgierski | Istvan-ak új autója van. Istvan-DAT nowy samochód.POSS jest |
‘Istvan ma nowy samochód’ (dosłowne: “Istvanowi jest jego nowy samochód”) |
| sheko [34] |
dādū t’āāgǹ íʃ-kǹ kìákɘ |
‘Ona ma dwoje dzieci.’ |
|
Tá cat beag agam. Níl madra agam. |
‘Mam małego kota.’ ‘Nie mam psa.’ |
|
| dir mašina b-ugo 1SG.GEN samochód III-być.PRES |
‘Mam samochód’ (dosłowne: ‘Mój samochód jest’) |
|
| tondano [37] |
si tuama sie wewean wale rua |
‘Mężczyzna ma dwa domy.’ |
DAT = celownik, POSS = posiadanie, 1 = pierwsza osoba, SG = liczba pojedyncza, PRES = czas teraźniejsza, ANIM = ożywiony, TOP = temat
Posiadanie jest wyrażane nie tylko w zdaniach, lecz również we frazach takich jak mój samochód, ojciec mojego przyjaciela itp. Jak widać w przykładach, dla potrzeb wyrażania posiadania język polski używa kilku technik: odmiennych form wyrazowych (ja – moja, my – nasz) czy różnych form fleksyjnych (ojciec – ojca). We wszystkich przypadkach relacja posiadania oznaczana jest na wyrazie lub konstrukcji, która wyraża posiadacza, podczas gdy przedmiot posiadany jest w formie podstawowej (zob. Tabela 1).
W języku węgierskim także możemy znaleźć kilka typów struktur, ale w odróżnieniu od polskiego, relacja posiadania zawsze oznaczana jest na przedmiocie posiadanym, podczas gdy posiadacz jest w formie podstawowej, np.: István könyv-e ‘książka Istvána’, a diák könyv-e ‘książka studenta’ (zob. Tabela 2). Przypomnijmy sobie przykład z deklaracją praw człowieka z początku rozdziału: w węgierskim relacja pomiędzy ‘prawa człowieka’ i ‘deklaracja’ jest oznaczana sufiksem -a na wyrazie nyilatkozat ‘deklaracja’.
emberi jogok nyilatkozat-a
ludzki prawa deklaracja-POSS
Po węgiersku w pierwszej i drugiej osobie posiadacz jest wyrażany sufiksem na rzeczowniku oznaczającym przedmiot posiadany, np. könyv-em ‘moja książka’, könyv-ed ‘twoja książka.
W innej węgierskiej konstrukcji oznaczany jest zarówno posiadacz, jak i przedmiot posiadany: István-ak könyv-e ‘książka Istvana’, a diák-ak a könyv-e (zob. Tabela 3).
| posiadacz | przedmiot posiadany | ||
| forma podstawowa | jako posiadacz | forma podstawowa | jako przedmiot posiadany |
| ja | mój | samochód | = |
| on | jego | dom | = |
| Jan | Jan-a | książka | = |
| mój przyjaciel | mojego przyjaciela | ojciec | = |
| human rights | of human rights | declaration | = |
| posiadacz | przedmiot posiadany | ||
| forma podstawowa | jako posiadacz | forma podstawowa | jako przedmiot posiadany |
| István | = | könyv ‘książka’ | könyv-e |
| diák ‘student’ | = | ||
| emberi jogok ‘praw człowieka’ |
= | nyilatkozat ‘deklaracja’ | nyilatkozat-a |
| én ‘ja’ | -(e)m | könyv | könyv-em |
| te ‘ty’ | -(e)d | könyv-ed | |
| posiadacz | przedmiot posiadany | ||
| forma podstawowa | jako posiadacz | forma podstawowa | jako przedmiot posiadany |
| István a diák ‘student’ (określony) |
István-ak a diak-ak |
a könyv ‘książka’ (określona) | a könyv-e |
Poniżej mamy inne przykłady tych trzech strategii:
| język | przykład | strategia: oznaczanie posiadania na… |
|
mashie-an maax ‘cena samochodu’ |
posiadaczu |
|
|
shunñe a-pojore ‘kajak mężczyzny’ ti-bba ‘mój mąż’ |
przedmiocie posiadanym |
|
|
cuku-ƞ hu:kiʔ-hy ‘ogon psa’ |
posiadaczu i przedmiocie posiadanym |
|
|
uƞ-bo uƞ-khim ‘mój dom’ kenci-bo kenci-khim ‘wasz dom’ (“dom was dwojga”) khokkuci-bo kʌci-khim ‘ich dom’ |
posiadaczu i przedmiocie posiadanym |
|
|
Warsé ci ‘kajak Warségo’ no cem ‘mój dom’ |
ani na posiadaczu, ani na przedmiocie posiadanym(rzadkie) |
Języki używają różnych konstrukcji dla wyrażenia różnego typu “posiadań”. Jedna może być stosowana przy stosunkach rodzinnych (‘moja siostra’) czy częściach ciała (‘mój nos’), a inna przy rzeczach, które można mieć na własność (‘mój dom’). Pierwszy typ nazywamy posiadaniem nierozdzielnym, a drugi – posiadaniem rozdzielnym. Poniższe przykłady pochodzą z austronezyjskiego języka saliba używanego w Papui-Nowej Gwinei (Mosel 1994):
| sinagu | moja matka | posiadanie nierodzielne |
| sinana | jego/jej matka | |
| tamana | jego/jej ojciec | |
| nimana | jego/jej ręka | |
| Maui nimana |
ręka Maui |
|
| yogu numa | mój dom | posiadannie rozdzielne |
| yona numa | jego/jej dom | |
| Maui yona numa | dom Maui |
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenia z języka daakaka (Vanuatu).
Jak pokazywać strukturę wyrazów i zdań
W tym rozdziale przykłady z różnych języków były opisywane za pomocą techniki zwanej “tłumaczeniem interlinearnym” lub “glosowaniem morfem po morfemie”. Metoda ta umożliwia zrozumienie przykładów z języków, których nie znamy. Dla przykładu pytanie z sekcji 4. w zachodniopapuaskim języku maybrat zaprezentowaliśmy w następujący sposób:
| ana | m-amao | Kumurkek | a |
| 3PL | 3-go | Kumurkek | Q |
Glosy z drugiej linijki mówią nam, że pierwsze słowo jest zaimkiem trzeciej osoby liczby mnogiej, drugie oznacza ‘iść’ i jest poprzedzone prefiksem oznaczającym trzecią osobę, trzecie jest nazwą własną, a czwarty to partykuła pytajna. Dysponując tymi informacjami możemy odtworzyć znaczenie całego zdania. Niemożliwe jest natomiast przetłumaczenie każdego słowa z przykładu w maybrat na słowa języka polskiego – nie ma na przykład morfemu oznaczającego trzecią osobę (w polskim istnieją osobne końcówki dla trzeciej osoby liczby pojedynczej, a osobne dla mnogiej, natomiast mamao w maybrat oznaczy zarówno ‘idzie’ jak i ‘idą’). Glosowanie jest w dużej mierze niezależne od struktury gramatycznej języka, na który tłumaczymy. Tłumaczone są tylko rdzenie leksykalne, a cała informacja gramatyczna zawarta w przykładzie jest oddawana za pomocą symboli takich jak PL dla liczby mnogiej, 3 dla trzeciej osoby. Symbole gramatyczne pisane są małymi kapitalikami i oczywiście ich znaczenie musi być wyjaśnione (przeważnie przy pomocy listy skrótów, tak jak poniżej). Wyrazy języka opisywanego są posegmentowane na morfemy, które oddzielone są od siebie łącznikiem, na przykład:
The boy scream-ed and ran quick-ly to his mother.
Następnie znaczenie każdego komponentu zapisywane jest dokładnie pod nim. Ilość łączników w obu linijkach musi się zgadzać. Jeśli segment zawiera więcej, niż jedno znaczenie, glosy dla tego segmentu oddzielane są od siebie kropkami. Rdzenie leksykalne tłumaczone są na język opisu (tzw. metajęzyk). Morfemy gramatyczne, w tym wyrazy funkcyjne, tłumaczy się przy użyciu odpowiednich symboli. Wyrazy funkcyjne mogą być tłumaczone za pomocą odpowiadających wyrazów funkcyjnych w języku opisu, jeśli takie są. Glosowanie powyższego zdania języka angielskiego na polski mogło by przebiegać następująco (wyrazy funkcyjne and i to mogły by być przeglosowane jako, odpowiednio: i i do):
| The | boy | scream-ed | and | ran | quick-ly | to | his | mother. |
| ART | chłopak | krzyczeć-PST | CONJ | biegać.PST | szybko-ADV | PREP | 3SG.M.POSS | matka |
Glosowanie to bardzo przydatne narzędzie w językoznawczym opisie, szczególnie jeśli chcemy porównywać bardzo różne od siebie języki. Czytanie glosów nie jest trudne, wymaga jedynie trochę wprawy. Poniżej przegłosowano przykłady z początku tego rozdziału – wyrażenie „powszechna deklaracja praw człowieka” w trzech językach europejskich:
estoński
| Inim-oigus-te | üld-deklaratsioon |
| człowiek-prawo-GEN.PL | powszechny-deklaracja |
niemiecki
| allgemein-e | Erklär-ung | der | Mensch-en-recht-e |
| powszechny-PL | deklarować-NOUN | ART.GEN.PL | człowiek-AFX-prawo-PL |
polski
| powszechn-a | deklaracj-a | praw | człowiek-a |
| general-NOM.SG.F | declaration-NOM.SG | right.GEN.PL | man-GEN.PL |
węgierski
| az | ember-i | jog-ok | egyetemes | nyilatkozat-a |
| ART | człowiek-ADJ | prawo-PL | powszechny | deklaracja-POSS |
Więcej szczegółów na temat glosowania dla bardziej zaawansowanych znajduje się na stronie http://www.eva.mpg.de/lingua/resources/glossing-rules.php.
Zajrzyj na Interaktywną Mapę i spróbuj rozwiązać ćwiczenie dla języka teop.
Zadanie
Sporządź interlinearne tłumaczenie jednego z artykułów Powszechnej Deklaracji Praw Człowieka (lub innego krótkiego tekstu).
Skróty używane do glosowania w tym rozdziale
| ADJ | przymiotnik |
| AFX | afiks |
| ANIM | ożywiony |
| ART | rodzajnik |
| CLF | klasyfikator |
| COND | tryb warunkowy |
| CONJ | spójnik |
| DAT | celownik |
| DUA | liczba podwójna |
| F | rodzaj żenski |
| GEN | dopelniacz |
| IMPF | aspekt niedokonany |
| IND | tryb orzekający |
| NOM | mianownik |
| NOUN | rzeczownnik |
| PERF | czas perfekt |
| PL | liczba mnoga |
| POSS | posiadanie |
| PREP | przyimek |
| PRES | czas teraźniejszy |
| PST | czas przeszły |
| Q | afiks lub partykuła pytajna |
| SG | liczba pojedyncza |
| TAM | wyznacznik czasu, aspektu i/lub trybu |
| TNS | czas |
| TOP | temat (to, o czym mowa) |
Sprawdź się!
Sekcja Sprawdź się! – Rozdział 3. Zobacz, ile już wiesz lub czego możesz się jeszcze dowiedzieć z Księgi Wiedzy Języków w Niebezpieczeństwie!
Przypisy:
[1] Tekst Powszechnej Deklaracji Praw Człowieka w różnych językach znajdziesz pod tym linkiem: http://www.ohchr.org/EN/UDHR/Pages/Introduction.aspx
[2] Odmiana – tworzenie form wyrazowych o różnych funkcjach gramatycznych, ale tym samym znaczeniu. Po polsku dzięki fleksji (odmianie) możemy stworzyć następujące formy czasownika widzieć: widzieć, widzę, widzi, widzieliśmy, widziany, widząc itd.
[3] Austronesian, Papua New Guinea. Źródło: Mosel 2007.
[4] Niger-Congo, Ghana. Źródło: Dorvlo 2008.
[5] Afro-Asiatic, Ethiopia. Źródło: Hellenthal 2010.
[6] Afro-Asiatic, Ethiopia. Źródło: Hellenthal 2010.
[7] Sino-Tibetan, Nepal. Źródło: N. P. Sharma i in. (online).
[8] Niger-Congo, Ghana. Źródło: Dorvlo 2008.
[9] Mon-Khmer, Thailand. Źródło: Rischel 1999
[10] Siouan, USA. Źródło: Albright 2000.
[11] Muskogean, USA. Źródło: Rubino 2013 (http://wals.info/chapter/27), za Kimball 1988: 440.
[12] Trans-New Guinea, Papua New Guinea. Źródło: Graz Database on Reduplication at http://reduplication.uni-graz.at/redup/, za Roberts 1991.
[13] Niger-Congo, Ghana. Źródło: Dorvlo 2008.
[14] Afro-Asiatic, Ethiopia. Źródło: Hellenthal 2010.
[15] Austronesia, Guam. Źródło: Cysouw 2013a (http://wals.info/chapter/39), za Topping 1973: 106-108.
[16] Sino-Tibetan, Nepal. Źródło: N. P. Sharma i in. (online).
[17] Lower Sepik, Papua New Guinea. Źródło: Seifart 2010, za Foley 1991: 141-161
[18] Austronesian, Indonesia. Źródło: Gil 2013, http://wals.info/chapter/55
[19] Iroquoain, USA. Źródło: Seifart 2010, za Blankenship 1997: 92
[20] Gwiazdka oznacza, że konstrukcja nie jest poprawna gramatycznie lub jest dopuszczalna tylko w wyjątkowych przypadkach, np. w poematach.
[21] Austronesian, Papua New Guinea.
[22] Niger-Congo, Ghana.
[23] Austronesian, New Zealand.
[24] Austronesian, Madagascar.
[25] Mayan, Mexico.
[26] Carib, Brazil.
[27] Nadahup, Brazil.
[28] Gunwinyguan, Australia.
[29] West Papuan, Papua i Indonesia; Źródło: Dryer 2013b (http://wals.info/chapter/116), za Dol 1999: 200.
[30] Uto-Aztecan, California. Źródło: Dryer 2013c (http://wals.info/chapter/92), za Norris 1986: 44.
[31] Afro-Asiatic, Ethiopia. Źródło: Dryer 2013b (http://wals.info/chapter/116), za Hayward 1990: 307.
[32] Afro-Asiatic, Ethiopia. Źródło: Hellenthal 2010.
[33] Eskimo-Aleut, Greenland. Źródło: Stassen 2013 (http://wals.info/chapter/117), za Fortescue 1984: 171.
[34] Afro-Asiatic, Ethiopia. Źródło: Hellenthal 2010.
[35] Indo-European, Ireland. Dane udostępnione przez Michael’a Hornsby’ego.
[36] Nakh-Daghestanian, Russia and Azerbaijan. Źródło: Stassen 2013 (http://wals.info/chapter/117), za Kalinina 1993: 97.
[37] Austronesian, Northern Sulawesi. Źródło: Stassen 2013 (http://wals.info/chapter/117), za Sneddon 1975: 175.
[38] Nakh Daghestanian, Caucasus. Źródło: Nichols & Bickel 2013 (http://wals.info/chapter/24), dane od Joanna Nichols.
[39] Isolate, Bolivia. Źródło: Van Gijn 2006.
[40] Miwok-Costanoan, USA (California). Źródło: Nichols & Bickel 2013 (http://wals.info/chapter/24), za Broadbent 1964: 133.
[41] Kiranti, Nepal. Data from Sharma i in. (online)
[42] Trans-New Guinea, Indonesia. Źródło: Nichols & Bickel 2013 (http://wals.info/chapter/24), za Voorhoeve 1965b: 136, 133.
Dalsze źródła:
Na temat różnych struktur językowych
- Dryer, Matthew & Haspelmath, Martin (eds.). 2013. The World Atlas of Language Structures Online. Munich: Max Planck Digital Library. Dostępny online: http://wals.info/
- Dürr, Michael & Schlobinski, Peter. 2006. Deskriptive Linguistik: Grundlagen und Methoden. Göttingen: Vandenhoeck und Ruprecht. [Trzecie wydanie, wcześniejsze wydania pt. „Einführung in die deskriptive Linguistik“]
- Haspelmath, Martin & Sims, Andrea. 2010. Understanding morphology. 2nd edition. London: Hodder Education.
- Payne, Thomas E. 1997. Describing morphosyntax. A guide for field linguists. Cambridge: Cambridge University Press.
- Payne, Thomas E. 2006. Exploring language structure: A student’s guide. New York: Cambridge University Press.
O gramatyce języka polskiego
- Słownik gramatyki języka polskiego. 2002. Pod redakcją Władzimierza Gruszczyńskiego i Jerzego Bralczyka. Warszawa: WSiP.
- Wróbel, Henryk. 2001. Gramatyka języka polskiego. Kraków: Od Nowa.
- Albright, Adam. 2000. The productivity of infixation in Lakhota. Nieopublikowany artykuł przygotowany do publikacji w UCLA Working Papers in Linguistics. Dostępny online: http://www.mit.edu/~albright/papers/Albright-LakhotaInfixation.pdf.
- Bauer, Laurie. 1988. Introducing linguistic morphology. Edinburgh: Edinburgh University Press.
- Corbett, Greville G. 2004. Number. Cambridge: Cambridge University Press.
- Corbett, Greville G. 2013. Number of genders, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 30. Dostępny online: http://wals.info/chapter/30
- Cysouw, Michael. 2013a. Inclusive/exclusive distinction in independent pronouns, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 39. Dostępny online: http://wals.info/chapter/39
- Cysouw, Michael. 2013b. Inclusive/exclusive distinction in verbal inflection, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 40. Dostępny online: http://wals.info/chapter/40
- Dorvlo, Kofi. 2008. A grammar of Logba (Ikpana). Proefschrift, Universiteit Leiden. Dostępny online: https://openaccess.leidenuniv.nl/bitstream/handle/1887/12945/Dorvlo%20Complete%20Text.pdf?sequence=1
- Dryer, Matthew S. 2013a. Order of subject, object and verb, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 81. Dostępny online: http://wals.info/chapter/81
- Dryer, Matthew S. 2013b. Polar questions, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 116. Dostępny online: http://wals.info/chapter/116
- Dryer, Matthew S. 2013c. Position of polar question particles, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 92. Dostępny online: http://wals.info/chapter/92
- Gil, David. 2013. Numeral classifiers, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 55. Dostępny online: http://wals.info/chapter/55
- Graz Database on Reduplication at http://reduplication.uni-graz.at/redup/ [30.05.2012]
- Hellenthal, Anneke Christine. 2010. A grammar of Sheko. Proefschrift, Universiteit Leiden. Dostępny online: http://www.lotpublications.nl/publish/articles/004092/bookpart.pdf
- Mosel, Ulrike. 1994. Saliba. München: LINCOM.
- Mosel, Ulrike, with Yvonne Thiesen. 2007. The Teop sketch grammar. Version 2007. Publikacja online: http://corpus1.mpi.nl/ds/imdi_browser/?openpath=MPI533750%23 [30.05.2012]
- Nichols, Johanna & Bickel, Balthasar. 2013. Locus of marking in possessive noun phrases, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 24. Dostępny online: http://wals.info/chapter/24
- Rischel, Jørgen. 1995. Minor Mlabri. A hunter-gatherer language of Northern Indochina. Copenhagen: Museum Tusculanum Press.
- Rubino, Carl. 2013. Reduplication, w: Dryer, Matthew & Haspelmath, Martin (red.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 27. Dostępny online: http://wals.info/chapter/27
- Sharma, Narayan P., Balthasar Bickel, Martin Gaenszle, Arjun Rai, and Vishnu S. Rai. Personal and possessive pronouns in Puma (Southern Kiranti). Online publication at DoBeS archive: xxx
- Seifart, Frank. 2010. Nominal Classification. Language and Linguistics Compass 4/8 (2010): 719-736.
- Stassen, Leo. 2013. Predicative possession, w: Dryer, Matthew & Haspelmath, Martin (eds.), The World Atlas of Language Structures Online. Munich: Max Planck Digital Library, rozdział 117. Dostępny online: http://wals.info/chapter/117
- Universal Declaration of Human Rights in various languages: http://www.ohchr.org/EN/UDHR/Pages/Introduction.aspx [15.05.2012]
- Van Gijn, Erik. 2006. A grammar of Yurakaré. Proefschrift (PhD thesis), Radboud Universiteit Nijmegen. Dostępny online: http://repository.ubn.ru.nl/bitstream/2066/41440/1/41440.pdf
- Prace cytowane w źródłach są podane poniżej:
- Blankenship, Barbara. 1997. Classificatory verbs in Cherokee. Anthropological Linguistics 39, 92-110.
- Broadbent, Sylvia M. 1964. The Southern Sierra Miwok language. University of Chicago Press.
- Dixon, Robert M. W. 1980. The languages of Australia. Cambridge: Cambridge University Press.
- Dol, Philomena. 1999. A grammar of Maybrat: A language of the Bird’s Head, Irian Jaya, Indonesia. University of Leiden.
- Foley, William A. 1991. The Yimas language of New Guinea. Stanford: Stanford University Press.
- Fortescue, Michael. 1984. West Greenlandic. Croom Helm.
- Hayward, Richard J. 1990. Notes on the Zayse Language. School of Oriental and African Studies, University of London.
- Kalinina, E. 1993. Sentences with non-verbal predicates in the Sogratl dialect of Avar, w: A. E. Kibrik (red.), The noun phrase in the Andalal dialect of Avara as spoken at Sogratl, 90-104. Eurotyp Working Papers.
- Kimball, Geoffrey D. 1988. Koasati reduplication, w: W. Shiplay (red.), In honor of Mary Haas, 431-442. Mouton de Gruyter.
- Norris, Evan J. 1986. A grammar sketch and comparative study of Eastern Mono. University of California at San Diego.
- Roberts, John R. 1987. Amele. Croom Helm.
- Roberts, John R. 1991. Reduplication in Amele, w: T. Dutton (red.), Papers in Papuan linguistics, No. 1, 115-146. Pacific Linguistics, A-73, 1991.
- Sneddon, James N. 1975. Tondano phonology and grammar. Australian National University.
- Voorhoeve, Clemens L. 1965. The Flamingo Bay dialect of the Asmat language. University of Leiden.
Tłumaczenie rozdziału z angielskiego: Radosław Wójtowicz.
powrót