Księga wiedzy
Rozdziały: 1 2 3 4 5 6 7 8 9 10
Lista języków wymienionych w Księdze Wiedzy i w innych działach strony.
POBIERZ i wydrukuj Księgę Wiedzy.
Sprawdź się!
Sekcja Sprawdź się! – Rozdział 10. Zobacz, ile już wiesz lub czego możesz się jeszcze dowiedzieć z Księgi Wiedzy Języków w Niebezpieczeństwie!
Autor rozdziału: Katarzyna Klessa
Formaty i struktury danych
Many popular data formats are based on the XML (Extensible Markup Language, see e.g. here), recommended e.g. by the CLARIN consortium (Common Language Resources and Technology Infrastructure, read more about format recommendations here, or refer to: Schmidt, Elenius, 2010:123-145). The XML is used as a basis for the output file format in many annotation tools. It enables storing multi-level annotation data and metadata together in one file.
In those cases when the data collected is of various types and formats (texts, photographs, speech or music files, video, etc.), an effective way to deal with them is to create a relation database. When XML files are stored with the use of a relation database (instead of being collected in a folder as a number of separate files), it is much easier and faster to search through them and to generate new files or statistics based on the contents of the original XMLs (see below for more information about databases).
Raw data, corpora and relational databases
Raw (primary) data is the original or source data that has not been previously systematized, validated or extensively processed. Thus, before making any use of them there is a need to perform at least basic work consisting of checking the actual data quality, quantity and contents. In situation when the linguistic data collection has an explicit aim and is done in a systematic way (often including simultaneous creation of annotations and metadata) it is common to use the term language corpus. Language corpora can be organized in various ways, e.g. as collections of files (e.g., stored in folders on hard disk) or with the use of relational database technology. A relational database is a powerful tool making it possible to better control and use data. The data in such a database is organized into tables connected to one another which enables searching through all tables, looking for relationships between various types of data, automatically edit data (e.g. bulk operations done for all or selected annotation files) as well as to share the data among many users who can access them in a controlled way without the risk of loosing information. Therefore, using a well structured relation database is advantageous over using collections of data files, especially when dealing with larger amounts of data. For example, benefits can be seen when several people want to annotate a number of sound files. In the case of working directly with sound and annotation files, quite a lot of manual work will be devoted to the distribution of files among annotators, controlling file versions, validating them etc., and it will be quite difficult to track the progress (timing, quality) of their work. Moreover, as with any manual work, it may happen that files are lost or mixed while exchanged among users and computers. A solution to this type of problem can be the use of a relation database (together with an appropriate file management software) enabling the control (distribution, inspection) over the annotations at any time, statistics of the annotators’ work time, automatic backup copies and many others.
Many of the existing databases are stored on on-line servers and can be accessed via the Internet which makes their use even more efficient. The servers are powerful computers with large capacity hard disks. Users can access data from their own personal computers after connecting to the server. Depending on software solutions the access to data can be granted in various ways, and the same database can be made available with the use of various types of software tools.
One example might be a client-server architecture developed for the development of a lexical database used within a Polish automatic recognition system (Klessa, et al., 2010). All lexicon entries and their descriptions are stored in a server, and the annotators can access and edit them using their own computers, but the changes are always saved in the server and thus can be immediately viewed by other users. In this particular case, the database management software distinguishes several levels of access rights for the users: some of them are only allowed to access the data while working in a local network (computers in laboratory rooms), and some have also rights to connect from outside, via the Internet. This type of software solution can provide very powerful and fast options for data processing but you need to install specific software on both the server and client (personal) computers.
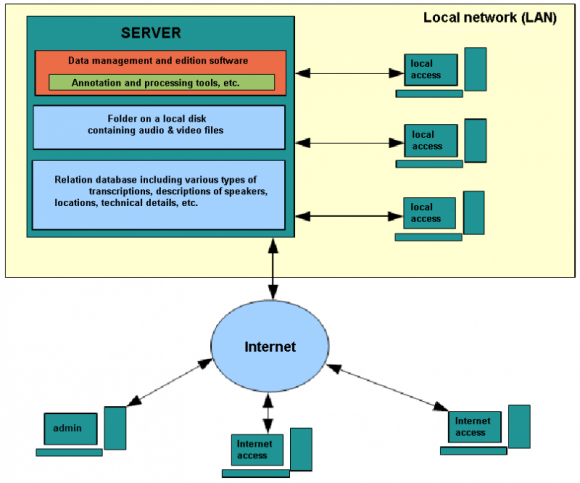
An illustration of client-server architecture.
A different example might be an on-line database architecture developed for the use with Internet browsers which does not require installation of any special software to access the data. It might be less efficient or slower than the client-server architecture with respect to processing certain types of data (e.g., management of sound file annotation tasks by a team of annotators), however, it might be extremely useful for sharing data included in language archives or for knowledge dissemination and is very often used for such purposes. Actually, most of the existing on-line language corpora make use of this type of technological solutions. An example might be the on-line database of Poland’s linguistic heritage. All data are stored in an on-line server and the same data can be accessed from two websites. One of them is an on-line database editor, available via any Internet browser for registered users (the database creators or data contributors). The second one is a publicly accessible website. The two websites differ with respect to both their functionality and layout. While the editor is a more technical website, not always very convenient in use but providing all necessary editing options, the website for general public presents the same contents in a more clear and reader-friendly way but without any editing options.
Data sharing, re-using and interoperability of formats and resources
Due to the fact that a variety of language archives co-exist and many new ones will most probably emerge, it is important to consider the issues of re-usability of language data as well as the possibility of flexible use of information from many various archives at a time. That is why one of the important contemporary technological and methodological challenges is to think of possibilities to fruitfully use data originally stored in various repositories. In order to meet the challenge, standards for sharing information and for dealing with data need to be established in a way enabling ‘translation’ of the formats from one to another. Another issue is the growing need for collaboration between the repository holders with a view to not only make the data accessible (which is comparably easy in the era of the Internet) but also to avoid unnecessary multiplication of the same data and to improve the styles of data presentation.
Let’s Revise! – Chapter 10
Go to the Let’s Revise section to see what you can learn from this chapter or test how much you have already learnt!
References
Klessa, K., Karpiński, M., Bałdys, O. Demenko, G., (2010). Speechlabs ASR. Polish Lexical Database for Speech Technology: Design and Architecture. Speech and Language Technology. 12/13, 2009/2010, Poznań, 191–207.
Klessa, K., Wicherkiewicz, T. (2014). Design and Implementation of an On-line Database for Endangered Languages: Multilingual Legacy of Poland. Proceedings of the 6th International Conference on Corpus Linguistics (CILC 6), Las Palmas de Gran Canaria, Spain, 22-24 May 2014.
Schmidt, T., Elenius, K. (2010). Multimedia Encoding and Annotation, Common Language Resources and Technology Infrastructure. Interoperability and Standards. CLARIN Deliverable D5.C-3 (pp.123-145).